Integer unit
It contains two components, the integer scheduler and integer execution units.
Integer Scheduler
It is based on a 3-way queuing system, also called reservation station (RS) which supplies the three execution units. Each of the 3 queue has room for 10 macro-op (8 in the previous Stars architecture: longer queues mean higher chance of re-ordering of instructions and thus more performance) for a total of 30 manageable macro-ops. Each RS divides the macro-ops in its arithmetic and logical address generation members.
Integer execution units
The integer execution unit (IE) consists of 3 elements (pipeline 0, 1 and 2). Each element is composed of an arithmetic logic unit (ALU) and an address generation unit (AGU). The IE is organized to coincide with the 3 macro-op dispach pipelines of the ICU, as shown in the figure.
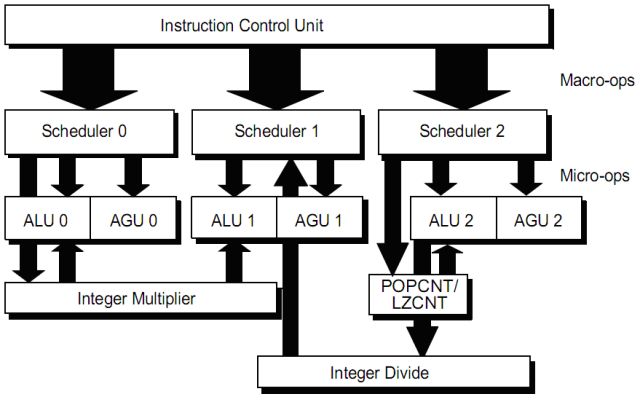
The macro-ops are broken into micro-ops in the schedulers. The micro-ops are executed when their operands are available both in the registers or in the result buses: in some interdependent instruction cases, it is not necessary to write the result into a register first and then read it in the next cycle, but you can connect the two instructions with an available result bus.
The micro-ops from a single macro-op can be executed out of order and also a particular integer pipeline can perform micro-ops from various macro-ops (one in the ALU and AGU) simultaneously.
Each of the three ALU is capable of performing logic, arithmetic functions, conditional processing, state flag processing and jump state calculation.
Each of the three AGU is able to calculate the linear address for a memory access or LEA instruction (which calculates the actual address of a datum without going in memory. Indeed LEA stands for Load Effective Address, which calculates and loads the actual address).
It's featured a unit for reads and writes in memory, which actually accesses the L1 data cache, described later (LSU, load and store unit).
The integer scheduler sends a completion signal to the ICU to indicate that a macro-op has been executed. The ICU will retire the instruction when all relevant macro-ops have been executed.
Almost all integer operations can be performed by either of the 3 ALU, with the exception of multiplication, division, LZCNT (leading zero count, ie counting the zeros of a binary number) and POPCNT (population count, ie count of '1' in a binary number).
The multiplications are handled by a pipelined multiplier, which is fed from the pipeline 0. To multiply, however the pipeline 0 and 1 are kept locked simultaneously, since the result of all the multiplication operations in the x86 architecture is double-precision and requires two specific target registers. During execution, the two pipeline 0 and 1 can not be used except for other multiplications (because the multiplier is pipelined). The multiplier of Llano has been further improved compared to previous generation Stars cores.
Similarly, the division uses the pipeline 1 and 2 and the integer divider is fed by pipeline 2, since the division in the x86 architecture starts from double-precision result and gives result and the rest in two separate registers. During the execution the two pipelines 1 and 2 can not be used except for other divisions (because the divisor is pipelined).
In the previous architecture (Stars core) there was not an hardware divider, but the division was a long VectorPath instruction blocking the pipelines 1 and 2 for as long as its long-running (in Llano divisions are also twice as fast) and since there was not a pipelined divider, only a division could be made at a time.
The POPCNT and LZCNT instructions are executed in an unit fed from the pipeline 2 and while it is running one of these instructions, the pipeline 2 is not usable by other instructions other than these two (because the unit is pipelined).
Ultimately a multiplication stops the execution of all non multiplicative instructions in the pipeline 0 and 1 and also of all the divisions, which also require the pipeline 1 to run. The division stops the execution of all non division instructions in the pipeline 1 and 2 and hence the multiplication, requiring the pipeline 1, and LZCNT and POPCNT instructions block all instructions that require the pipeline 2 and therefore also the divisions.
