 Toc, toc, anzi tick-tock! Chi bussa alla porta? E’ Intel che regolarmente ogni due anni ci consegna la sua nuova architettura. Quest’anno Intel sembra bussare sottovoce e il rinnovo dell’architettura è senz’altro meno entusiasmante di quanto visto ad esempio con Sandy Bridge, almeno a primo impatto. Le novità di Haswell sono poche ed abbastanza nascoste, ma ci sono. Scopriamole quindi insieme queste novità, testando sul campo sia la CPU che la IGP delle due proposte Intel destinate agli appassionati di overclock: il Core i7 4770K e il Core i5 4670K. Se qualcuno ha già intuito l’allusione presente nel titolo di questa recensione, lo invitiamo a fare un passo indietro, perché l’affermazione non è così scontata. Haswell riserva ancora delle sorprese che sviscereremo nel corso di questo articolo. Diffidate delle analisi superficiali! Al solito siamo un po’ (o meglio molto) in ritardo con i tempi di pubblicazione (complice Intel stessa e contrattempi vari), ma l’obiettivo è sempre quello di fornire un’analisi completa che non si ferma alle prime impressioni. A qualche mese di distanza, dopo molti test effettuati e qualche news su quello che ci aspetta per il futuro possiamo dare un giudizio più che esaustivo su queste nuove CPU.
Toc, toc, anzi tick-tock! Chi bussa alla porta? E’ Intel che regolarmente ogni due anni ci consegna la sua nuova architettura. Quest’anno Intel sembra bussare sottovoce e il rinnovo dell’architettura è senz’altro meno entusiasmante di quanto visto ad esempio con Sandy Bridge, almeno a primo impatto. Le novità di Haswell sono poche ed abbastanza nascoste, ma ci sono. Scopriamole quindi insieme queste novità, testando sul campo sia la CPU che la IGP delle due proposte Intel destinate agli appassionati di overclock: il Core i7 4770K e il Core i5 4670K. Se qualcuno ha già intuito l’allusione presente nel titolo di questa recensione, lo invitiamo a fare un passo indietro, perché l’affermazione non è così scontata. Haswell riserva ancora delle sorprese che sviscereremo nel corso di questo articolo. Diffidate delle analisi superficiali! Al solito siamo un po’ (o meglio molto) in ritardo con i tempi di pubblicazione (complice Intel stessa e contrattempi vari), ma l’obiettivo è sempre quello di fornire un’analisi completa che non si ferma alle prime impressioni. A qualche mese di distanza, dopo molti test effettuati e qualche news su quello che ci aspetta per il futuro possiamo dare un giudizio più che esaustivo su queste nuove CPU.
Pubblicità
Haswell: lentamente verso il multithreading
Qualche anno fa ci saremmo aspettati per il 2013 CPU a 16 core per la fascia enthusiast e forse anche per la mainstream. Tuttavia, entrambe e piattaforme sembrano ancora andare a gonfie vele anche con soli 4 core. Intel di anno in anno tende a migliorare le prestazioni in single threading senza preoccuparsi troppo della corsa all’integrazione di un numero esorbitante di core. Perché?
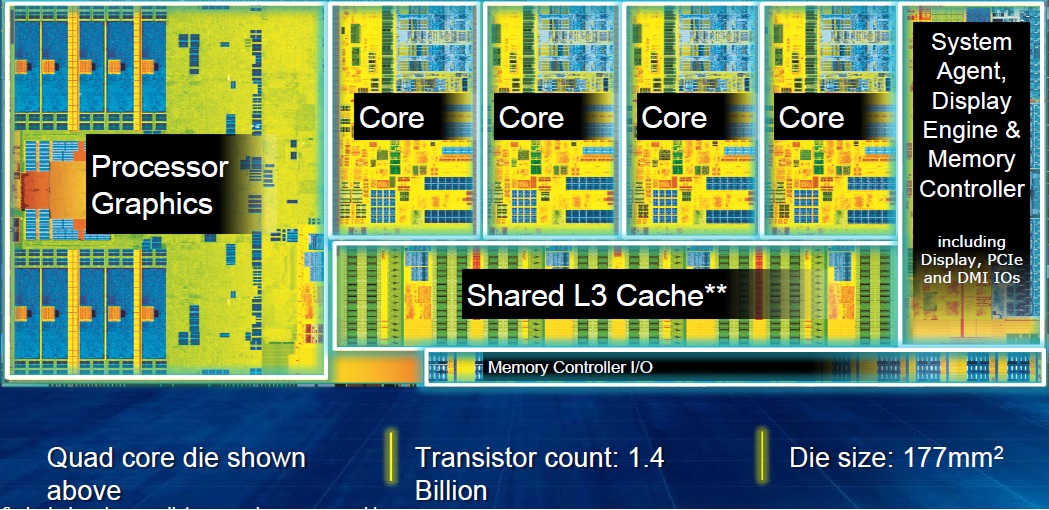
Il motivo principale è la difficoltà di implementazione del multithreading, sia a livello hardware che software. Per fare “8” non è sufficiente fare “4+4”, aggiungere core alle attuali architetture impone degli importanti vincoli progettuali per l’accesso alla cache L3 condivisa. Per la fascia mainstream quest’ultima è condivisa anche con la IGP, quindi aggiungere core significa aumentare le latenze di accesso, nonostante la recente implementazione in Sandy Bridge (e successive) del Token Ring Bus, un sistema che prometteva già una buona scalabilità.
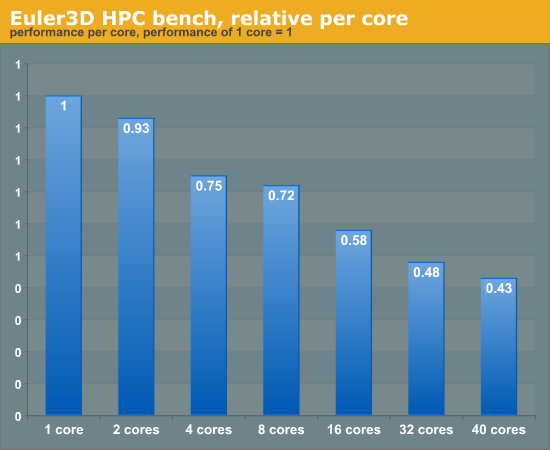
Se guardiamo a questo test effettuato da Anandtech con il benchmark Euler3D, possiamo comprendere quanto si possa perdere in efficienza all’aumentare del numero di core utilizzati. Il motivo di questa perdita di efficienza e dello scaling non lineare delle prestazioni è da ricercare spesso nella difficoltà di accedere alle stesse risorse presenti in memoria da parte di thread differenti. Al fine di evitare problemi di sincronizzazione dei dati, e di conseguenza inconsistenza, i programmatori di software multhreaded utilizzano un meccanismo detto di lock all’atto dell’accesso ad una risorsa presente in memoria. Il lock blocca quella risorsa fintanto che è utilizzata da quel thread e ne impedisce l’accesso da parte di altri thread. Per limitare i tempi di sviluppo, però, il lock viene spesso effettuato su strutture dati di grandi dimensioni, piuttosto che sulla cella di memoria specifica a cui si accederà in quella linea di codice. Ciò comporta che spesso gli altri thread sono inutilmente in attesa del rilascio della risorsa, riducendo il throughput finale dell’applicazione. Cosa c’entra in tutto questo Intel? Ebbene, di fronte a questo problema, spesso di natura software, Intel viene incontro ai programmatori direttamente a livello hardware, introducendo le estensioni TSX (Transactional Synchronization eXtensions).
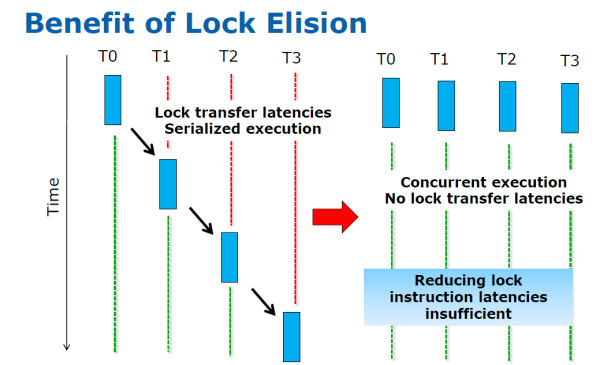
La principale di queste estensioni riguarda le istruzioni HLE (Hardware Lock Elision). Queste istruzioni permettono di eseguire il codice che richiederebbe un lock, senza un lock! In pratica se 4 Thread devono accedere alla medesima risorsa, utilizzando le istruzioni HLE si suppone che esse non siano “concorrenti” e vengono eseguite contemporaneamente, senza attendere che ogni thread rilasci la risorsa. Se a livello hardware viene identificata una sovrascrittura di una cella di memoria e quindi una inconsistenza nei dati, l’intero processo viene abortito e rieseguito di nuovo, questa volta con un sistema di lock tradizionale.
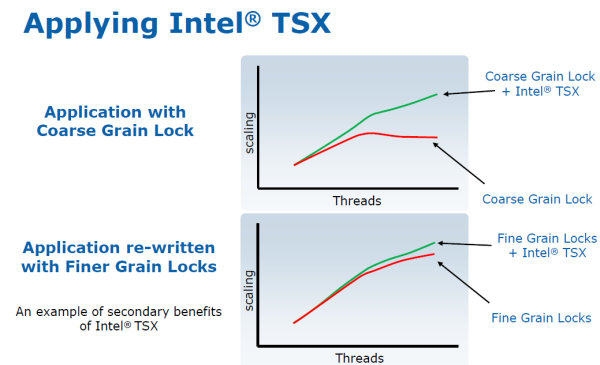
Alla prova dei fatti le estensioni TSX riescono a migliorare le prestazioni di applicazioni multithreading in modo sostanziale rispetto ad un codice che faccia uso di lock “grossolani” ovvero su strutture più grandi delle effettive risorse accedute. L’incremento diventa sostanziale aumentando il numero di core (logici), ovvero di thread eseguibili contemporaneamente. Il software multithreaded compilato con queste istruzioni (Visual Studio 2012 e GCC v4.8 sono già compatibili) dovrebbe permettere consistenti incrementi prestazionali sulle CPU con architettura Haswell e successive, rimanendo allo stesso tempo compatibile con le precedenti CPU che non supportano le TSX!
Le TSX rappresentano dunque un importante passo avanti, senza il quale la corsa ad un maggior numero di core nella CPU sarebbe probabilmente inutile.